LLM Integration for Enterprise: Complete Implementation Guide for 2026
Complete guide to enterprise LLM integration. Learn architecture patterns, security strategies, cost optimization, and implementation roadmaps for production-scale large language model deployments.
LLM integration for enterprise represents one of the most significant technology shifts in business operations. In 2026, organizations are moving beyond experimentation to production-scale deployments that transform customer service, internal operations, and product capabilities through large language model integration.
This comprehensive guide covers architecture patterns, security considerations, cost optimization, and real-world implementation strategies for enterprise LLM integration.
Understanding Enterprise LLM Integration
LLM integration for enterprise means connecting large language models (GPT-4, Claude, Gemini, Llama) to your business systems, data, and workflows. Unlike consumer AI chatbots, enterprise integrations require:
- Security and compliance aligned with industry regulations
- Data privacy that keeps sensitive information within your control
- Scalability to handle thousands of concurrent users
- Reliability with SLAs and uptime guarantees
- Cost predictability for budgeting and ROI tracking
- Auditability for compliance and debugging
For background on building production systems, see our guide on autonomous AI agents for business.
Enterprise LLM Integration Patterns
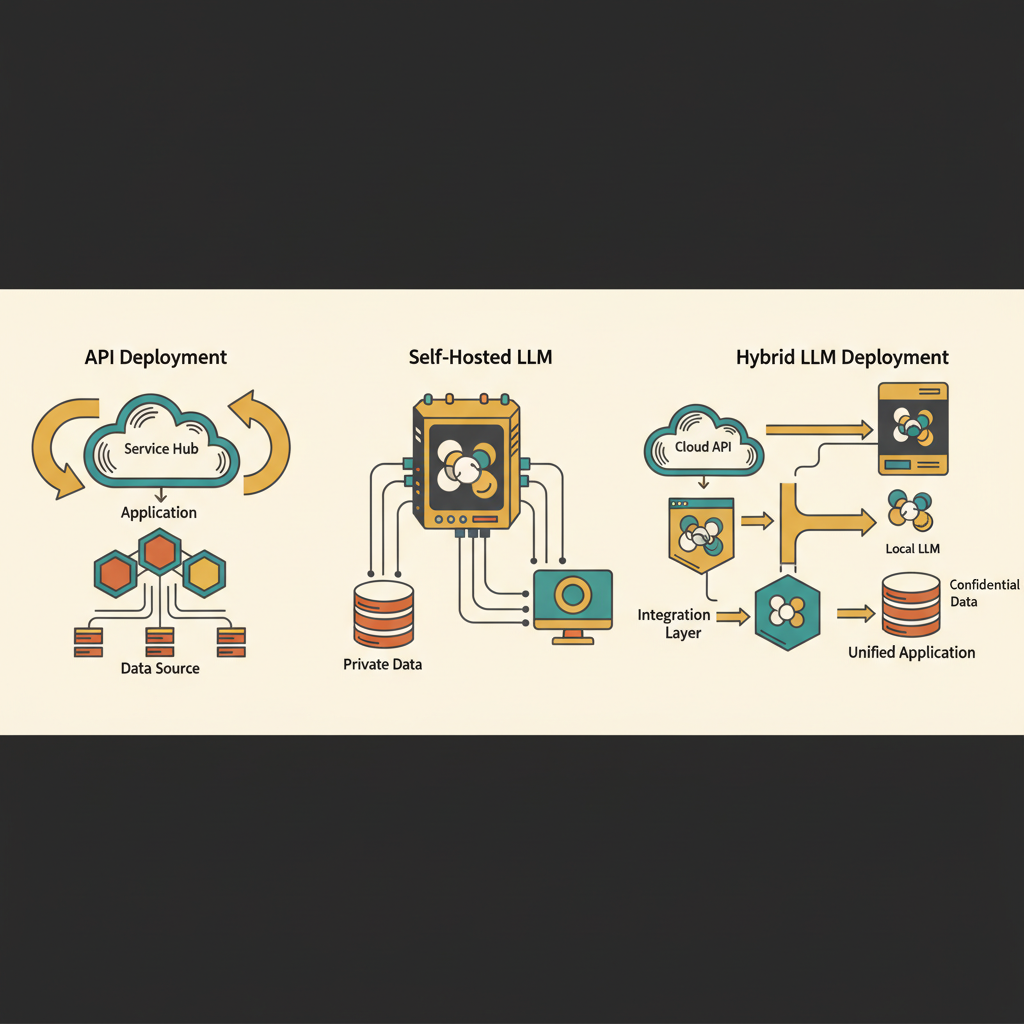
1. API-First Integration
Best for: Quick deployment, leveraging existing LLM providers
Connect to hosted LLM APIs (OpenAI, Anthropic, Google) through your application layer.
Advantages:
- Fast time to market
- No infrastructure management
- Access to latest models
- Built-in scaling
Challenges:
- Data leaves your infrastructure
- Ongoing API costs
- Dependency on external service
- Limited customization
Cost: $100-$10,000/month depending on volume
2. Self-Hosted Models
Best for: Maximum data control, compliance requirements
Deploy open-source models (Llama, Mistral, custom fine-tuned models) on your infrastructure.
Advantages:
- Complete data privacy
- Full customization
- Predictable costs at scale
- No vendor lock-in
Challenges:
- Requires ML infrastructure expertise
- Initial setup complexity
- Ongoing maintenance overhead
- Hardware/cloud compute costs
Cost: $5,000-$50,000/month for compute + engineering
3. Hybrid Approach
Best for: Balancing control, cost, and capability
Use external APIs for general tasks, self-hosted models for sensitive data.
Advantages:
- Optimal cost-performance tradeoff
- Data stays internal where needed
- Leverage best-in-class models
- Flexibility by use case
Challenges:
- More complex architecture
- Multiple systems to maintain
- Routing logic required
Cost: $2,000-$15,000/month depending on split
Security Considerations for Enterprise LLM Integration
Data Privacy
Encrypt data in transit and at rest: Use TLS 1.3 for API calls, AES-256 for storage
Implement data anonymization: Strip PII before sending to external LLMs
Use private endpoints: Azure OpenAI, AWS Bedrock provide VPC-isolated access
Audit data flows: Track what data goes where for compliance
Access Control
Role-based access control (RBAC): Limit LLM access by user role API key management: Rotate keys regularly, use secrets management Rate limiting: Prevent abuse and cost overruns Session management: Timeout idle sessions, clear conversation history
Prompt Injection Protection
Input validation: Sanitize user inputs before LLM processing Output filtering: Check responses for leaked data or harmful content Guardrails: Define allowed actions and information boundaries Monitoring: Log and alert on suspicious patterns
Integration Architecture Components
1. LLM Gateway Layer
Central routing and management for all LLM requests:
- Load balancing across providers (OpenAI, Anthropic failover)
- Caching for repeated queries (50-80% cost reduction)
- Rate limiting and quota management
- Request/response logging for audit and debugging
- Cost tracking by user, department, or use case
2. Context Management
Provide LLMs with relevant business context:
- Vector databases (Pinecone, Weaviate) for semantic search
- Document retrieval from knowledge bases
- Database integration for real-time business data
- API connectors to CRM, ERP, helpdesk systems
3. Orchestration Layer
Manage complex multi-step workflows:
- Agent frameworks (LangChain, AutoGen) for tool usage
- Workflow engines for multi-agent coordination
- Error handling and retry logic
- Human-in-the-loop approval flows
4. Monitoring and Observability
Track performance and quality:
- Latency monitoring (p50, p95, p99)
- Cost tracking per interaction
- Quality metrics (user feedback, task success)
- Error rates and failure analysis
For details, see our guide on AI agent testing and monitoring.
Enterprise LLM Use Cases
Customer Service Automation
- Tier 1 support handling (60-80% automation rate)
- 24/7 availability across channels
- Multilingual support without staffing overhead
- Instant access to knowledge bases and documentation
Internal Knowledge Management
- Conversational search across company documents
- Onboarding assistance for new employees
- Policy and procedure Q&A
- Meeting summarization and action item extraction
Code and Development
- Code review and suggestions
- Documentation generation
- Debugging assistance
- Test case generation
Sales and Marketing
- Lead qualification and scoring
- Personalized email generation
- Content creation and optimization
- Competitive analysis
Learn more about AI chatbot development cost for budgeting these projects.
Cost Optimization Strategies
1. Implement Aggressive Caching
Cache responses for common queries (40-70% hit rate typical):
- Exact match caching: $0 cost for repeated questions
- Semantic caching: Similar questions use cached answers
- TTL management: Balance freshness vs. cost
2. Use Smaller Models Where Appropriate
- GPT-3.5 for simple tasks ($0.50 vs $15 per million tokens)
- Gemini Flash for high-volume, low-complexity needs
- Fine-tuned smaller models for domain-specific tasks
3. Optimize Prompts
- Shorter prompts = lower costs
- Clear instructions reduce retry loops
- Few-shot examples improve accuracy, reduce iterations
4. Batch Processing
- Process multiple items per API call where possible
- Schedule non-urgent tasks for off-peak pricing
- Aggregate similar requests
5. Set Budget Alerts
- Per-user spending limits
- Department-level quotas
- Automatic throttling at thresholds
Compliance and Governance
GDPR Compliance
- Data processing agreements with LLM providers
- Right to deletion implementation
- Data portability capabilities
- Privacy impact assessments
HIPAA for Healthcare
- Business associate agreements (BAAs)
- Audit logs for all data access
- Encryption requirements
- Access control validation
SOC 2 for SaaS
- Security controls documentation
- Regular penetration testing
- Incident response procedures
- Third-party audits
Industry-Specific
- Financial services: PCI DSS, SOX compliance
- Legal: Attorney-client privilege protections
- Government: FedRAMP authorization
Implementation Roadmap
Phase 1 (Months 1-2): Pilot
- Select one high-value use case
- Deploy with limited user group
- Gather feedback and metrics
- Validate ROI hypothesis
Phase 2 (Months 3-4): Expansion
- Extend to broader user base
- Add additional use cases
- Optimize costs based on usage patterns
- Implement advanced monitoring
Phase 3 (Months 5-6): Scale
- Enterprise-wide deployment
- Multi-channel integration
- Advanced features (voice, multilingual)
- Self-service for business users
Phase 4 (Ongoing): Optimization
- Continuous model evaluation
- Cost optimization refinement
- New use case development
- Model fine-tuning
Common Pitfalls
Underestimating integration complexity: Connecting LLMs to existing systems takes longer than expected
Insufficient prompt engineering: Poor prompts lead to low-quality outputs and user frustration
Ignoring latency requirements: 5-second responses lose users
No cost controls: Runaway API costs from improper usage
Skipping pilot phase: Going straight to production without validation
Inadequate security review: Compliance issues discovered late in deployment
Conclusion
LLM integration for enterprise in 2026 is a mature capability with proven ROI across industries. Success requires careful architecture planning, robust security implementation, and phased rollout with clear success metrics.
The winning approach balances speed to value with production-grade quality: start with high-impact use cases using API-first integration, then evolve toward hybrid or self-hosted solutions as scale and compliance requirements grow.
Organizations that treat LLM integration as a strategic platform—not a one-off project—position themselves for continuous innovation as model capabilities advance.
Build AI That Works For Your Business
At AI Agents Plus, we help companies move from AI experiments to production systems that deliver real ROI. Whether you need:
- Custom AI Agents — Autonomous systems that handle complex workflows, from customer service to operations
- Rapid AI Prototyping — Go from idea to working demo in days using vibe coding and modern AI frameworks
- Voice AI Solutions — Natural conversational interfaces for your products and services
We've built AI systems for startups and enterprises across Africa and beyond.
Ready to explore what AI can do for your business? Let's talk →
About AI Agents Plus Editorial
AI automation expert and thought leader in business transformation through artificial intelligence.


